Context
Grounded Question Answering (QA) is usually the last step of a RAG pipeline: given a question and a set of documents retrieved from the corpus, an LLM must generate an answer. We expect the LLM to cite which document each piece of information is coming from, as depicted below. When no precise answer is in the documents, the LLM should indicate it in its answer. In that case, if some related information is available in the documents, the LLM can add it to the answer to show the corpus is not completely off-topic with respect to the question.
![Schema showing an example depending on whether the references contain a precise answer, only related information or no information. For each case there is an example of references and ground truth answer. The question is common to the three cases : What is the relationship between Pluto and Neptune. Case 1 : the references contain a precise answer. Reference 1 : More than 200 objects in 2:3 resonance are known (meaning they complete exactly 2 revolutions around the Sun when Neptune completes 3), among which are Pluto and its moons. Reference 2 : Pluto’s axis of rotation is tilted at 57.5 degrees relative to its orbital plane, which is quite high and unusual in the Solar System. Reference 3 : On the left: view of a cardiac cycle, of a systolic-diastolic oscillating flow, characteristic of circulatory arrest. Ground truth answer : The 3:2 orbital resonance relationship between Pluto and Neptune means that for every 3 revolutions of Neptune around the Sun, Pluto completes 2 [reference 1 citation]. Case 2 : References only contain related information. The reference 1 containing a precise information was removed, the two others are left. Ground truth answer : No document seems to precisely answer your question. However, the documents indicate that : Pluto’s axis of rotation is tilted at 57.5 degrees [reference 2 citation]. Case 3 : References contain no answer nor related information. Reference 1 and 2 were removed, only reference 3 which is off topic if left. Ground truth answer : No document seems to precisely answer your question.](./static/images/grounded_qa_cases.png)
This task is difficult to evaluate due to the wide variety of errors an answer can contain, such as superfluous information, missing relevant details from references, incorrect claims that no document answers the question, citation mistakes and so on. Some attempts to define metrics and automatize the evaluation of this task have been made (RAGAS, DeepEval), however, these approaches didn't cover all the failure modes we were interested in.
Most of these approaches rely heavily on the LLM-as-a-Judge method. While this technique can be powerful, it is crucial to first assess the ability of an LLM to accurately evaluate this Grounded QA task with respect to our metrics.
It is tempting to consider using an LLM to verify the evaluations generated by an evaluator LLM (which was assessing LLM's answers). However, this could quickly lead down a rabbit hole of endless AI-on-AI evaluations. This is why we developed GroUSE: a unit testing suite designed to evaluate the evaluators (pronounced "graouse").

The GroUSE dataset
GroUSE (Grounded QA Unitary Scoring of Evaluators) is a dataset of unitary tests used to check if a Grounded QA evaluator is giving the scores we expect. Each test contains:
- a Grounded QA sample (consisting of a question and references),
- a ground truth answer to the question,
- an answer to evaluate (which may or may not contain an error),
- a list of expected grades.
![This image is titled 'A simplified sample of GroUSE' and showcases an example of how to evaluate the accuracy and relevance of an answer. The structure is divided into five main sections: 1) Question: 'What is the relationship between Pluto and Neptune?'. 2) A list of two references. Reference 1: 'More than 200 objects in 2:3 resonance are known (meaning they complete exactly 2 revolutions around the Sun when Neptune completes 3), among which are Pluto and its moons.' Reference 2: 'Pluto rotates on its axis every 6.387 days, which is 6 days, 9 hours, and 17 minutes. Its axis of rotation is tilted at 57.5 degrees relative to its orbital plane, which is quite high and unusual in the Solar System.' 3) Ground Truth Answer: 'The 3:2 orbital resonance relationship between Pluto and Neptune means that for every 3 revolutions of Neptune around the Sun, Pluto completes 2 [reference 1 citation].' 4) Answer to Evaluate: 'The 3:2 orbital resonance relationship between Pluto and Neptune means that for every 3 revolutions of Neptune around the Sun, Pluto completes 2 [reference 1 citation]. Pluto’s axis of rotation is tilted at 57.5 degrees [reference 2 citation].' 5) Expected Notes: A rating system different evaluation criteria: Answer Relevancy: less than 4 (indicated in orange). Completeness: 5 (green). Useful: undefined (grey). Faithfulness: 1 (green). Positive Acceptance: undefined (grey). Negative Rejection: undefined (grey).](./static/images/one_sample.png)
In our framework, judge LLMs evaluate the quality of a grounded QA answer according to 6 metrics intended to capture all the failure modes of the task:
- Answer relevancy assesses the relevance of the information provided in the answer regarding the question, using a Likert scale (1 to 5).
- Completeness also uses a Likert scale to evaluate whether all relevant information from the documents is present in the answer.
- Faithfulness is a binary score that checks if all facts in the answer are accurate and correctly attributed to the corresponding document.
- Usefulness is only evaluated when the answer states there is no precise answer in the references and provides related information. It is a binary score that determines if the additional information is indeed useful and relevant to the question.
- Positive Acceptance and Negative Rejection are binary scores indicating a true positive and a true negative respectively in identifying whether the question is answerable.
The GroUSE dataset comprises 144 samples organized into 9 sets. Each set addresses the same question and draws from largely similar references, with slight variations in the answers. These small modifications are tailored to fit a predefined typology of 16 test types, which are designed to assess whether an evaluator correctly penalizes all failure modes and rewards accurate answers across a diverse range of scenarios. The image below displays four samples along with their corresponding test types. For instance, test type 14 assesses whether the faithfulness score is set to 0 when there is a citation mistake.

GroUSE includes an additional set of tests meant to help users engineer their prompts and try to obtain the best evaluator possible before checking its performances on the 9 other sets. Using this "train set", we iterated on the prompts, making our best effort to craft the best prompts possible for each of the tested models before measuring how many tests they passed. The "train set" is kept small to imitate the real-world scenario where the user has a limited number of samples to optimize its prompts.
Benchmarking the evaluation abilities of models
The structure of the GroUSE dataset allows for presenting a model's results in a matrix format, where each row represents the model's performance on a specific test type, and each column corresponds to its performance on a particular question. This format reveals, for example, that GPT-4 struggles with test type 16, which involves an answer containing information that distorts one of the references, leading to a low expected faithfulness but good relevancy and good completeness. Moreover, Llama-3 70B struggles the most with test type 7, a test in which we include an *absurd* fact in the references and mention this fact in the answer. Despite the fact seeming incorrect, since it's present in the references, high scores are expected. Test type 7 allows to check that the model doesn't use its internal knowledge and refers solely to the references to evaluate the metrics.
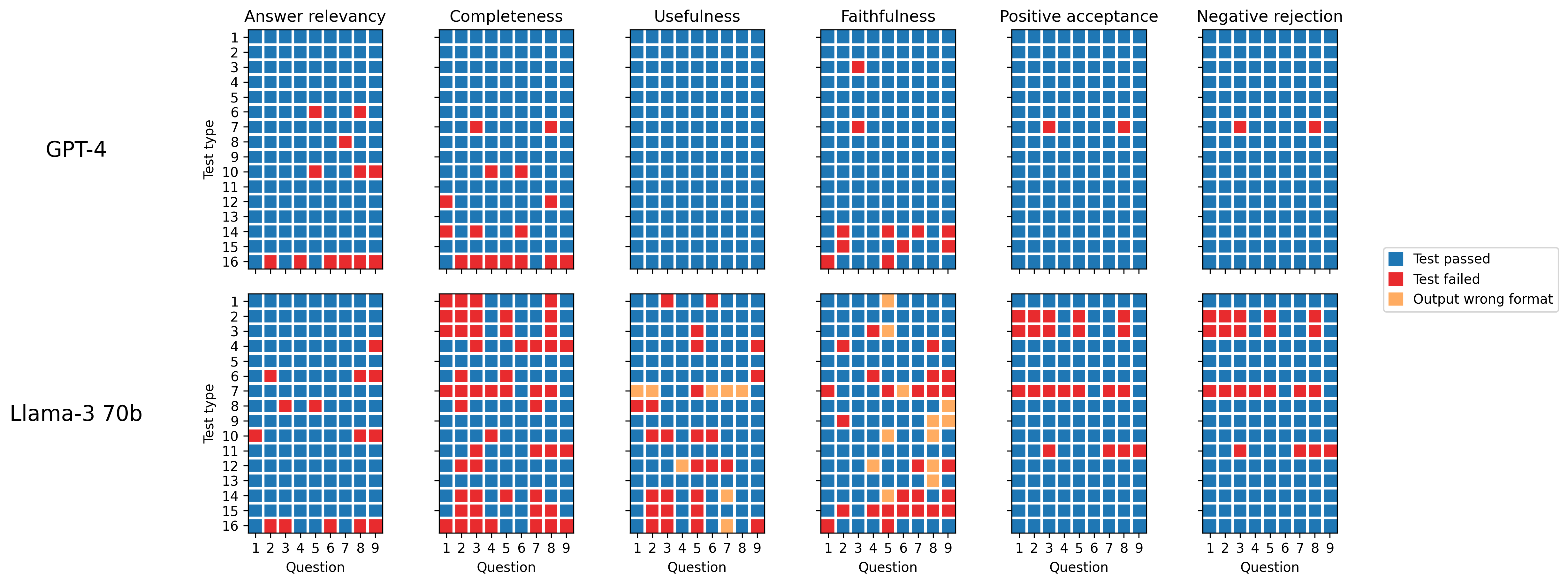
For a more compact view, we can also calculate the percentage of tests each model passes for each metric:
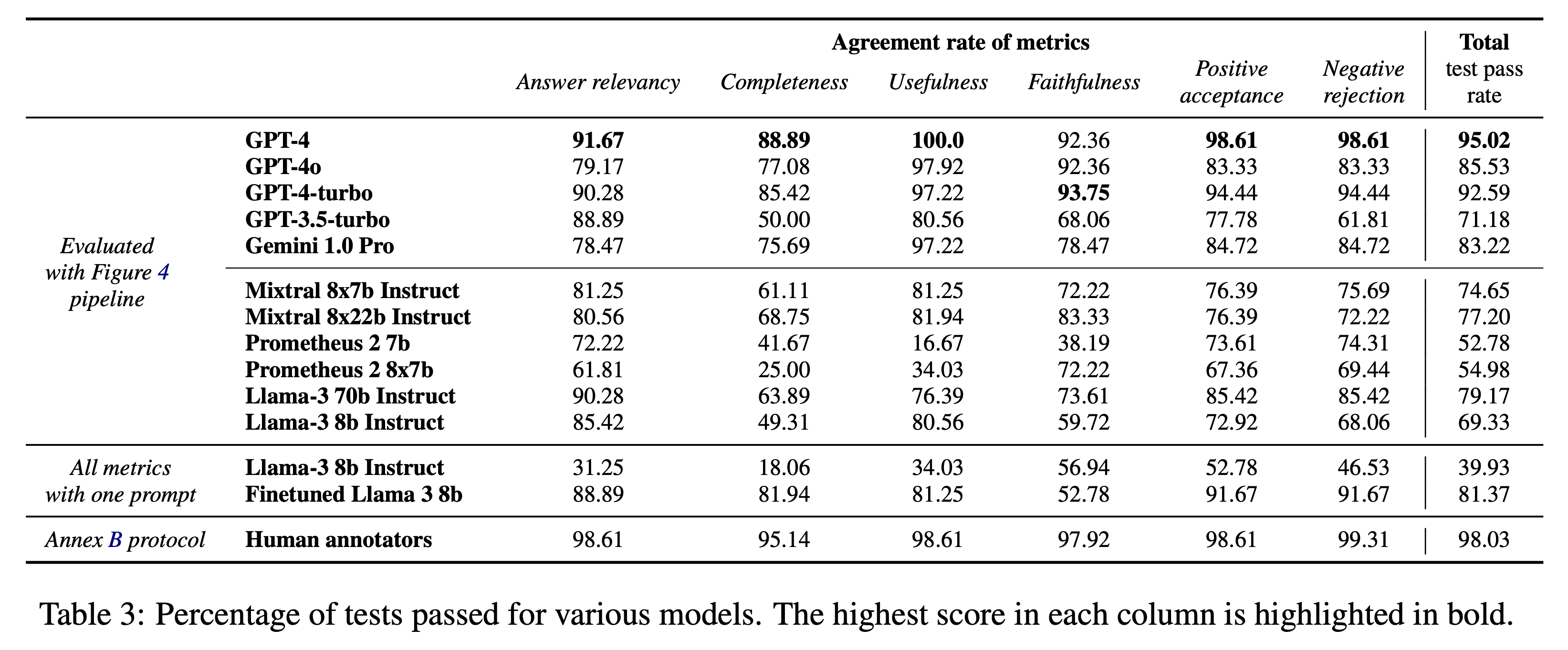
The strongest evaluator models are GPT-4 for closed-weights models, with a pass rate of 95%, and Llama-3 70b for open-weights with 79%. The human performance on this dataset is 98%. The hardest metric to evaluate is completeness, for LLMs and humans alike.
Improving an open source model
To demonstrate the gap between open-weights and closed-weights models can be narrowed, we finetuned a Llama-3 8b model on traces of evaluations by GPT-4. Aiming to develop a model capable of solving the task in a single call, we concatenated the metric-specific responses from GPT-4 into a single output and followed a similar process for the input, resulting in a dataset of 1200 samples. We finetuned the Llama-3 8b on 1k samples of this dataset, and used the rest as a test set. We measured the model's progression both on GroUSE and by measuring the correlation between GPT-4's grades and the finetuned model's grades on the test set.
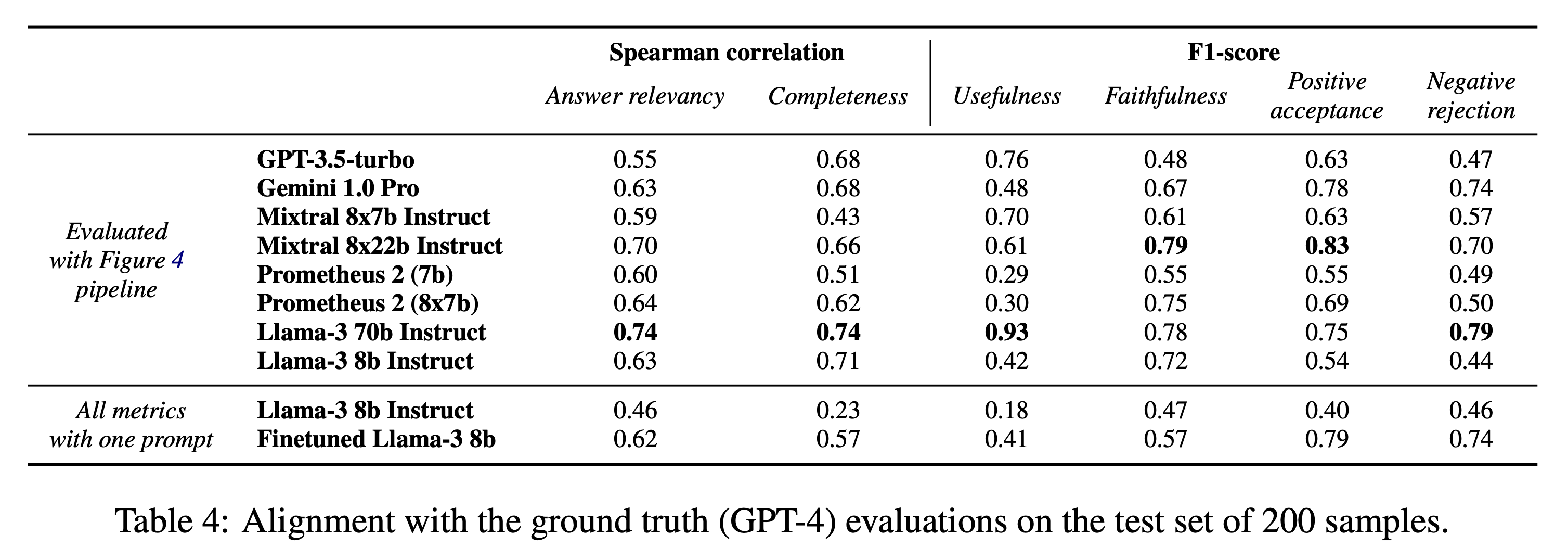
Finetuning significantly enhances the evaluation capabilities of Llama-3, as evidenced by the substantial improvement in pass rates, going from a 40% to a 83% test pass rate. A similar progress can be seen on the correlation measures, however it is worth noting that the finetuned model has similar correlation levels than the 0-shot Llama-3 8b with evaluating one metric per prompt. Although this approach demonstrated significant improvements, it would be beneficial to explore the effects of finetuning larger models, which could potentially yield even better performance.
Correlation or GroUSE ?
Our results reveal a discrepancy between GroUSE pass rates and correlation with GPT-4's grades. While Prometheus 2 7b and finetuned Llama-3 8b show similar correlations with GPT-4 on answer relevancy, their GroUSE pass rates differ significantly, with Llama-3 8b outperforming Prometheus 2 7b. Confusion matrices reveal that Prometheus 2 has better overall agreement with GPT-4 but struggles with extreme cases (1, 5 and NaN cases), while finetuned Llama-3 excels in extreme cases but lacks correlation in intermediate ones.
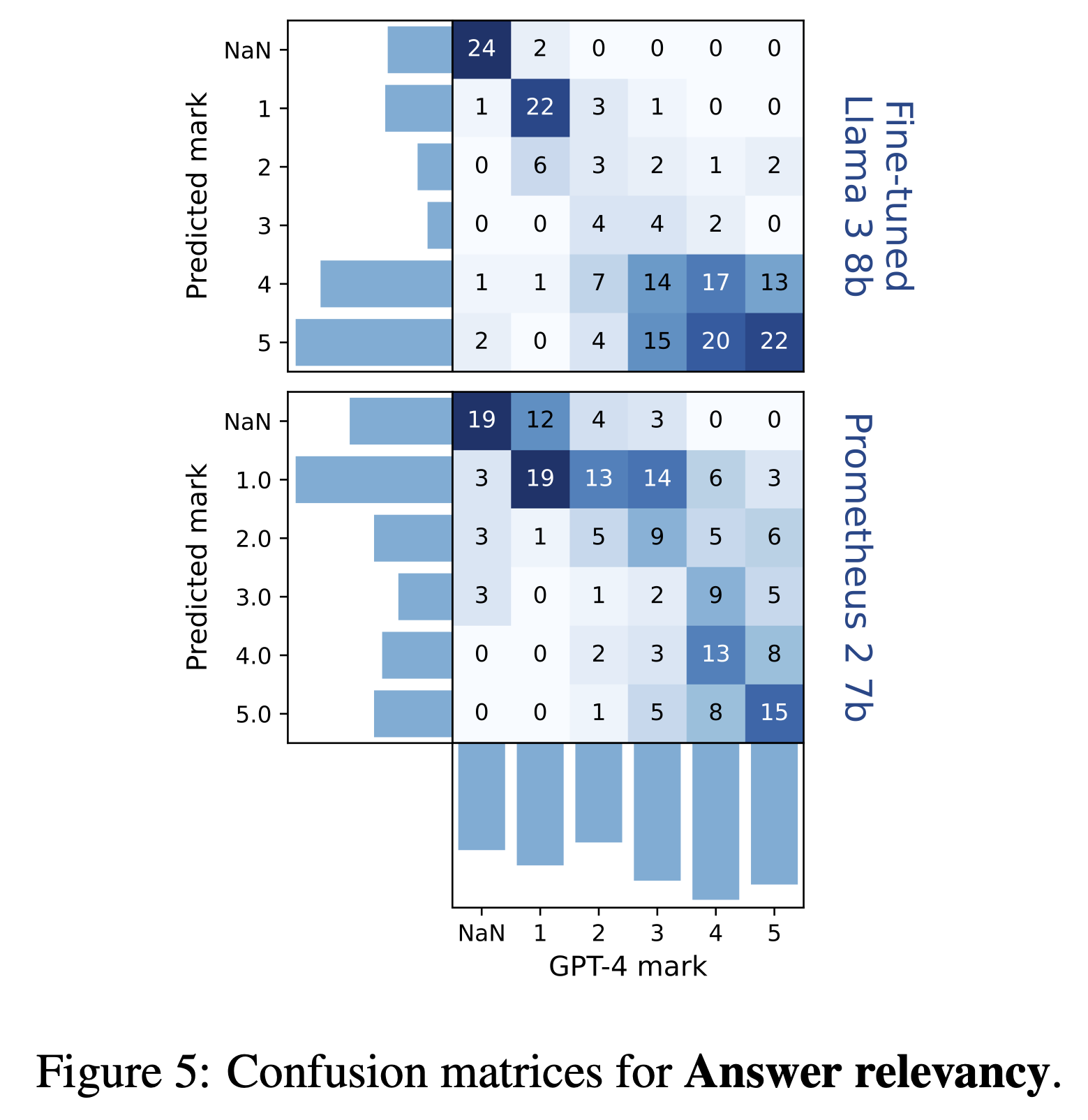
This finding suggests that a high correlation with GPT-4's judgments does not necessarily equate to a high unit test pass rate. A judge model can share the same relative preferences as GPT-4 (indicated by strong rank correlation) but still lack the same calibration on precise reference cases (very good answers, subtle mistakes, etc.), resulting in poor performance on judgment unit tests.
Conclusion
To conclude briefly:
- GroUSE is a dataset that allows to check if a model attributes the expected score on a wide range of cases.
- Using the LLM-as-a-Judge approach, GPT-4 was the strongest closed weights evaluator and Llama-3 70B the best open weights evaluator.
- We demonstrated that a model evaluation abilities can improve with finetuning on a stronger model's evaluations.
- We showed that correlation with a strong evaluator does not necessarily imply a good score on the unit tests. These measures are complementary: correlation with GPT-4 indicates agreement in relative preference, while GroUSE pass rate measures precise calibration on practical reference cases.
If you want to evaluate your RAG pipeline with our GPT-4 prompts, or even meta-evaluate your RAG evaluator on GroUSE, a python package is available at github.com/illuin-tech/grouse !
BibTeX
@misc{muller2024grouse,
title={GroUSE: A Benchmark to Evaluate Evaluators in Grounded Question Answering},
author={Sacha Muller and António Loison and Bilel Omrani and Gautier Viaud},
year={2024},
eprint={2409.06595},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2409.06595},
}